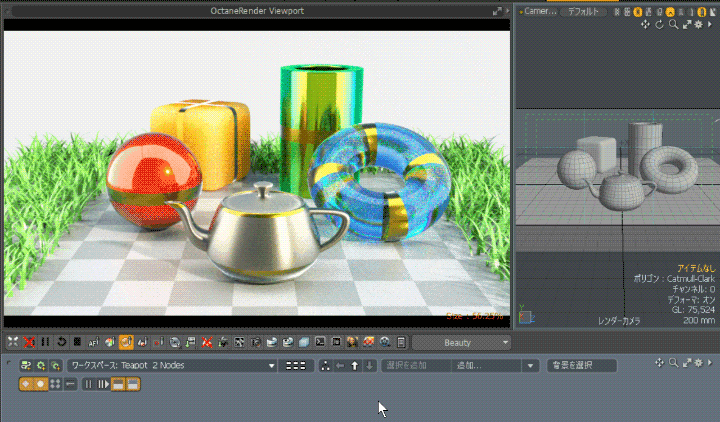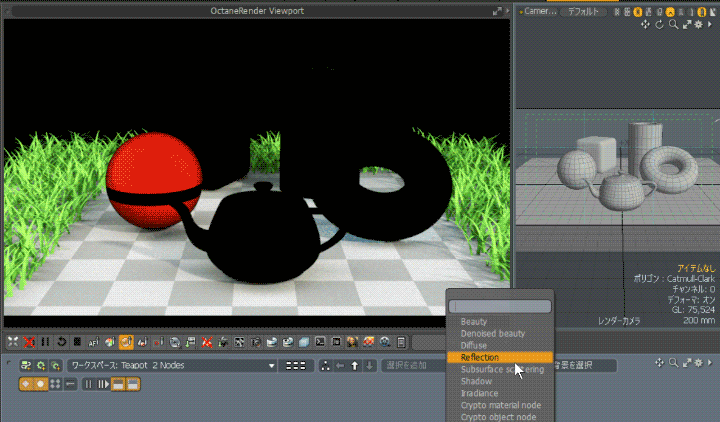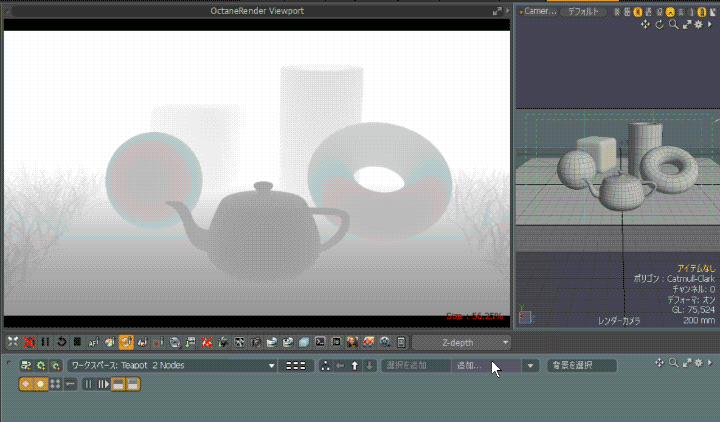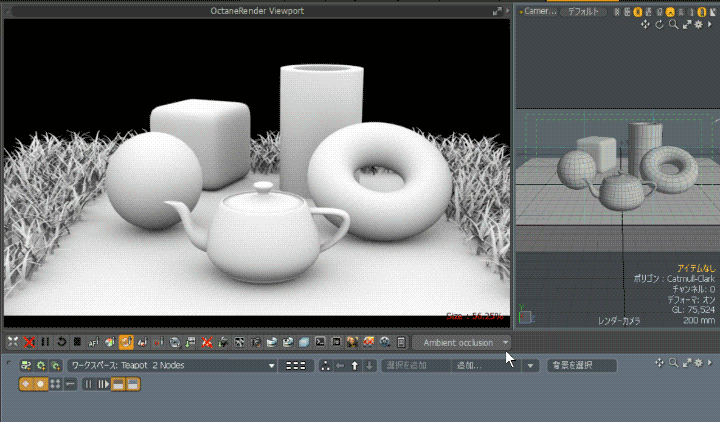
Octane Render for modo の AOV 出力について書いてみます。 modo 17 からGPUレンダラー「Octane Render Prime」がバンドルされるようになりました。modo の「レンダー […]
Tips
Octane Render for modo の AOV 出力
![]()
Octane Render for modo の AOV 出力について書いてみます。 modo 17 からGPUレンダラー「Octane Render Prime」がバンドルされるようになりました。modo の「レンダー […]
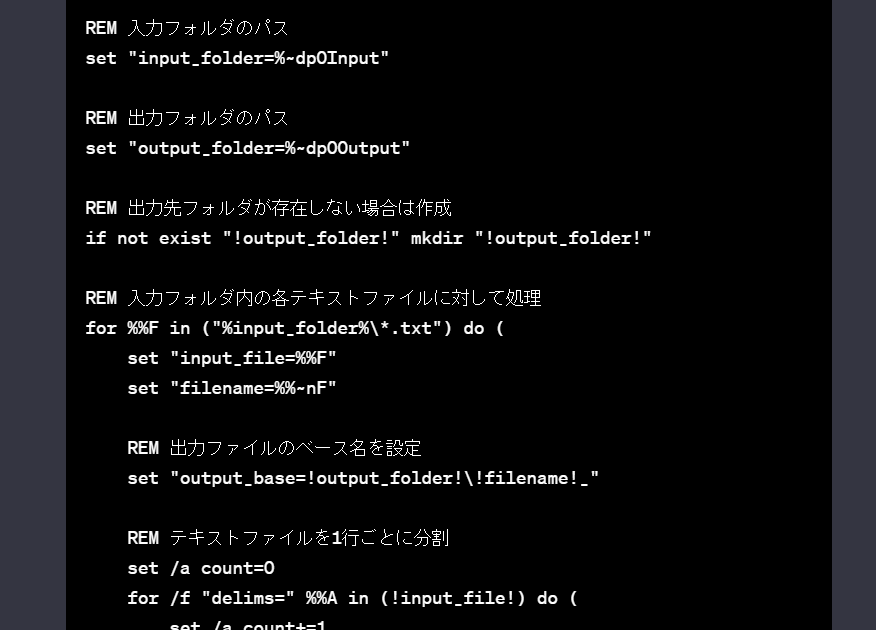
VOICEPEAKのコマンドラインを使用して、テキストファイルを読み込んで.wavファイルを出力してみた。2回目のチャレンジです。 前回コマンドラインからテキストファイルを読み込んで.wavファイルを出力しました。しかし […]
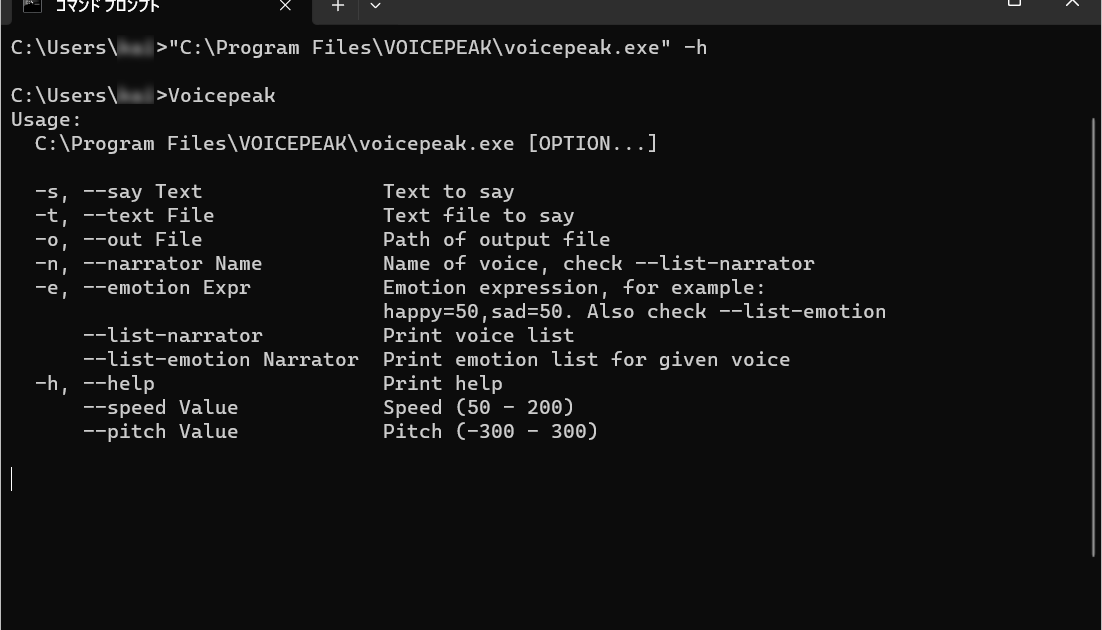
2023年01月13日に公開された VOICEPEAK 1.2.1 の新機能として、コマンドラインからテキストファイルを読み込んで .wav を出力出来るようになりました。 VOICEPEAKの使用頻度が高いのですが、テ […]
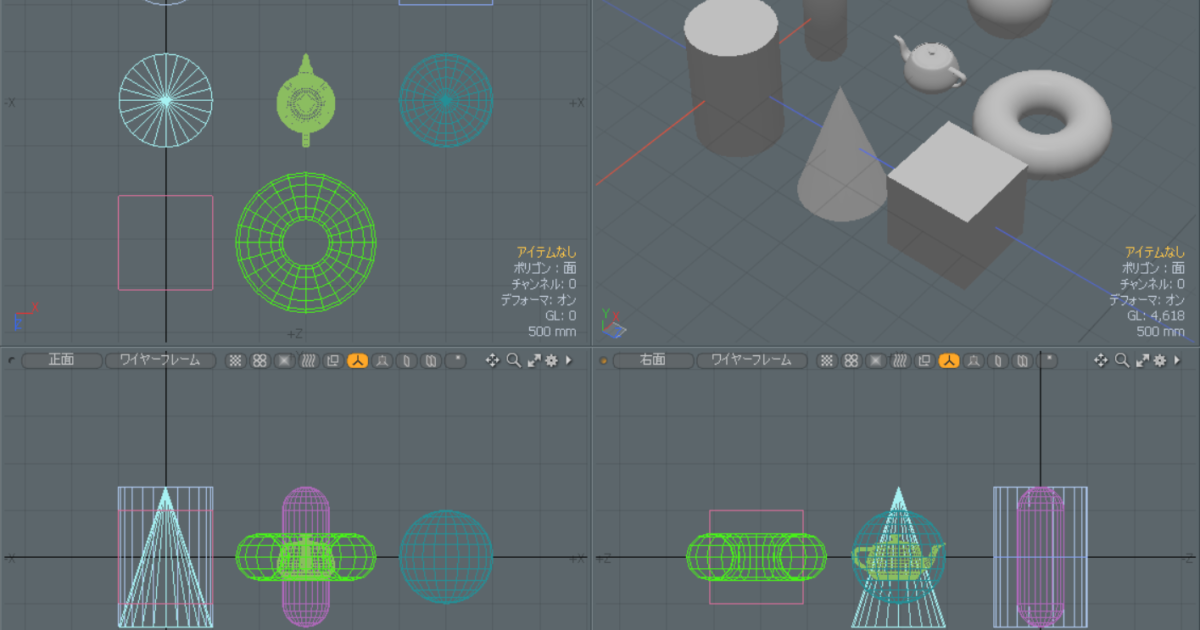
三面図のワイヤーフレーム色を変更する方法について書いてみます。 modoは初期バージョンから「パース」表示だけでモデリングできるように作られています。ですが昔からの慣れで、三面図を表示しながらモデリングして […]
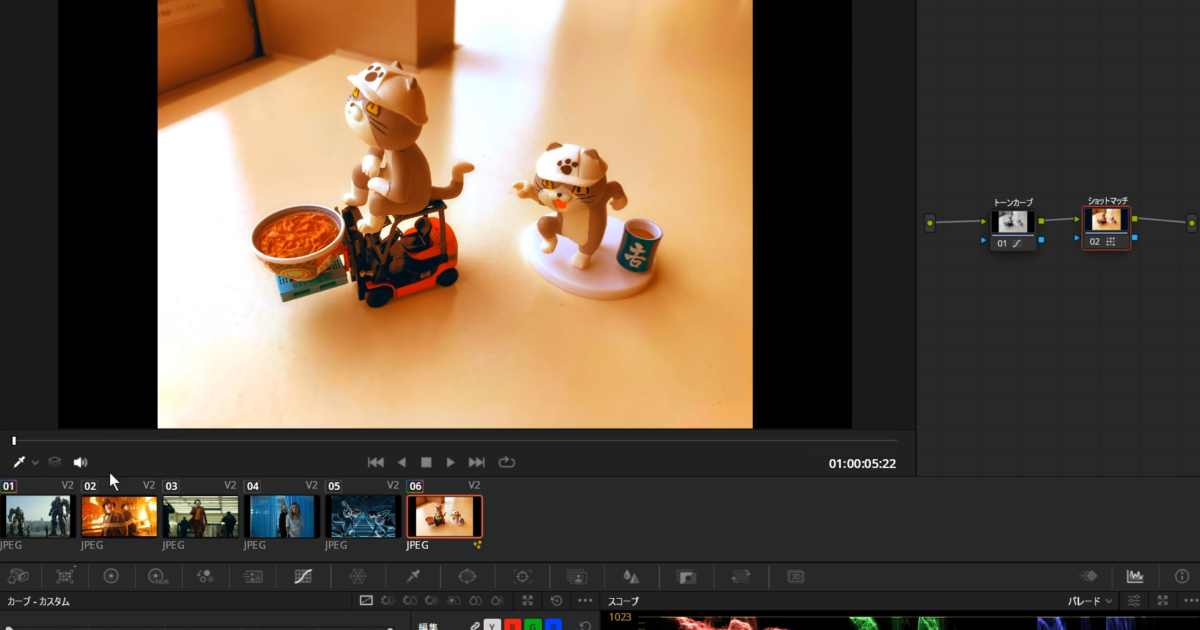
DaVinci ResolveのAIを使用した自動ショットマッチ機能のメモです。 指定した画像のルックに合わせて自動でカラーグレーディングしてくれます。精度はぱっと見近いかもという程度で、最終的には手動で調整する必要があ […]
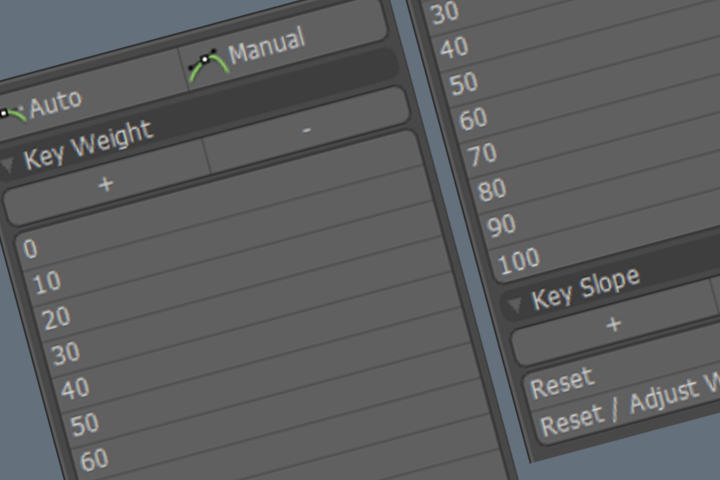
modoでキーウェイト(ハンドルの長さ)値を設定するプリセットボタンを作ったので、作成方法について書いてみます。 スロープとウェイト はじめにスロープとウェイトの確認方法を紹介します。 modoでカーブのス […]
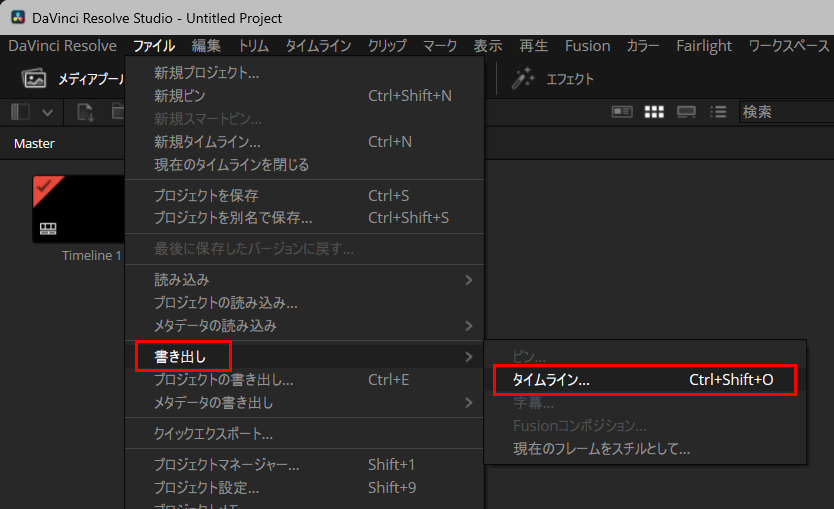
DaVinci Resolve でカット編集したデータを、After Effects に読み込む方法について書いてみます。.xmlや.aaf形式を使用すると DaVinci Resolveで編集したタイムラインをAfte […]

DaVinci Resolve Speed Editorを購入したので、使い方を覚えるためにSpeed Editorの操作まとめを書いてみます。 Speed Editorは、映像編集ソフト「DaVinci Resolve […]

DaVinci Resolve Speed Editorを購入したので、使ってみた感想を書いてみます。 Speed EditorはDaVinci Resolve専用の編集キーボードです。DaVinci Resolve S […]

modoでCryptomatteをレンダリングする方法について書いてみます。modo 14.2でmPathがCryptomatteに対応しました。Cryptomatteを使用するとAfter Effectsでマテリアル単 […]
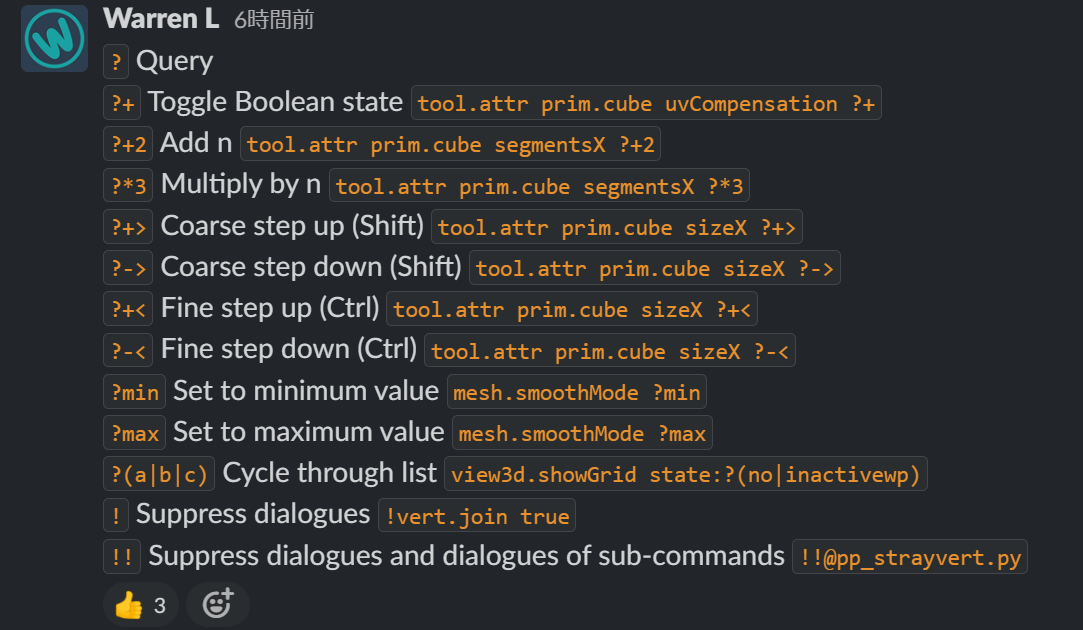
modoのSlackでコマンドの演算子をWarren Lさんがまとめて投稿してたのでメモしておきます。 コマンドを実行するときに構文や演算子を追加すると、自動化で便利に使えたりします。 https://foundry-m […]

modoでプロシージャルな鎖(リンクチェーン)を作る方法について書いてみます。鎖はアクセサリーや駐車場スタンドなど身近でよく使われているので、CGで作る機会の多い定番の題材です。 modoには鎖を表現する方法がいくつかあ […]
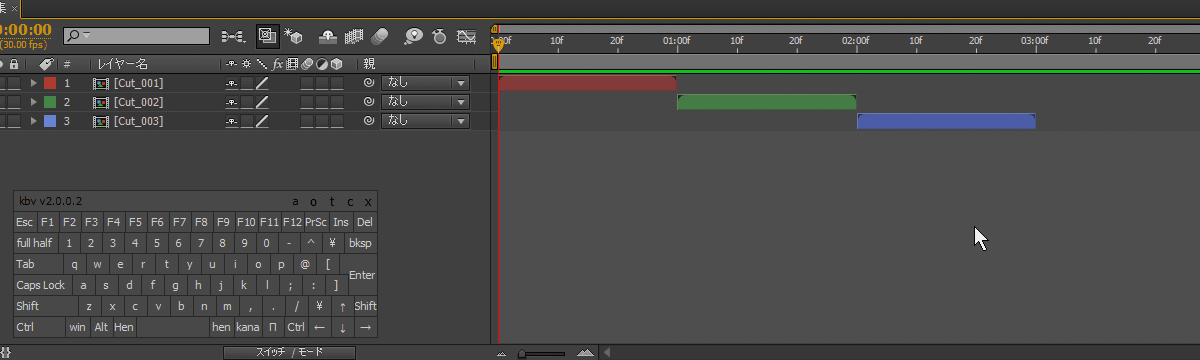
After Effectsのタイムライン操作に関するショートカットをまとめたページです。 After Effectsのタイムラインには様々な便利機能があるのですが、メニューにコマンドが表示されていないくて、ショートカット […]

modoのスペースキー ショートカットをmodo 15.0以前の動作に戻す方法について書いてみます。 modo 15.1からスペースキーを押した場合の動作が変更になりました。 modo 15.0以前は、スペースキーを押す […]
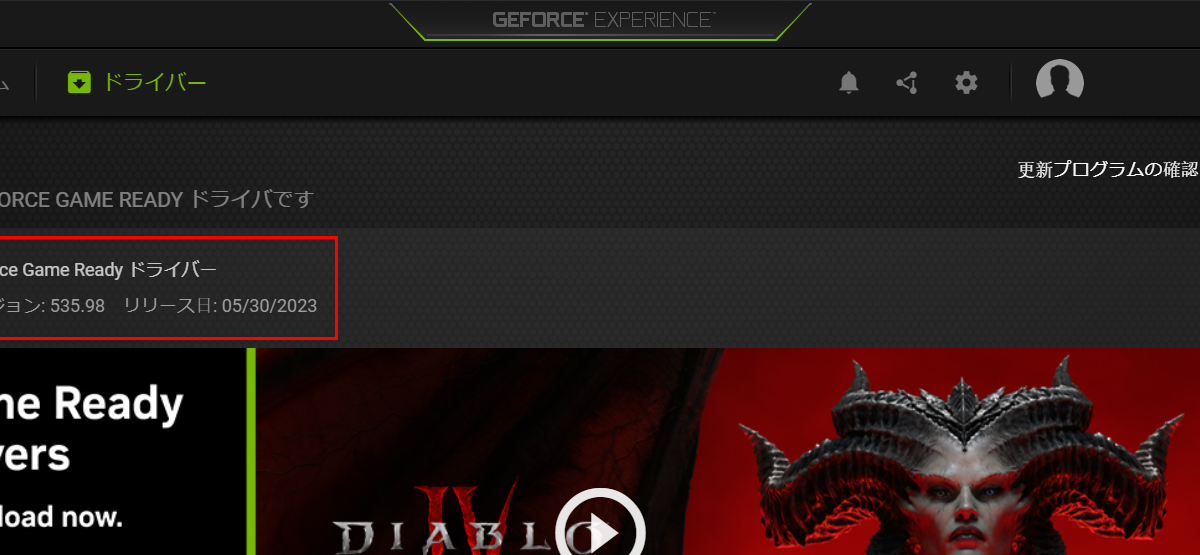
modoを使用する場合の、NVIDIAコントロールパネル設定について書いてみます。 NVIDIA ドライバー 535.98 と、 modo 16.1V6 の組み合わせでAVPのパフォーマンスが20~30%向上するとのこと […]